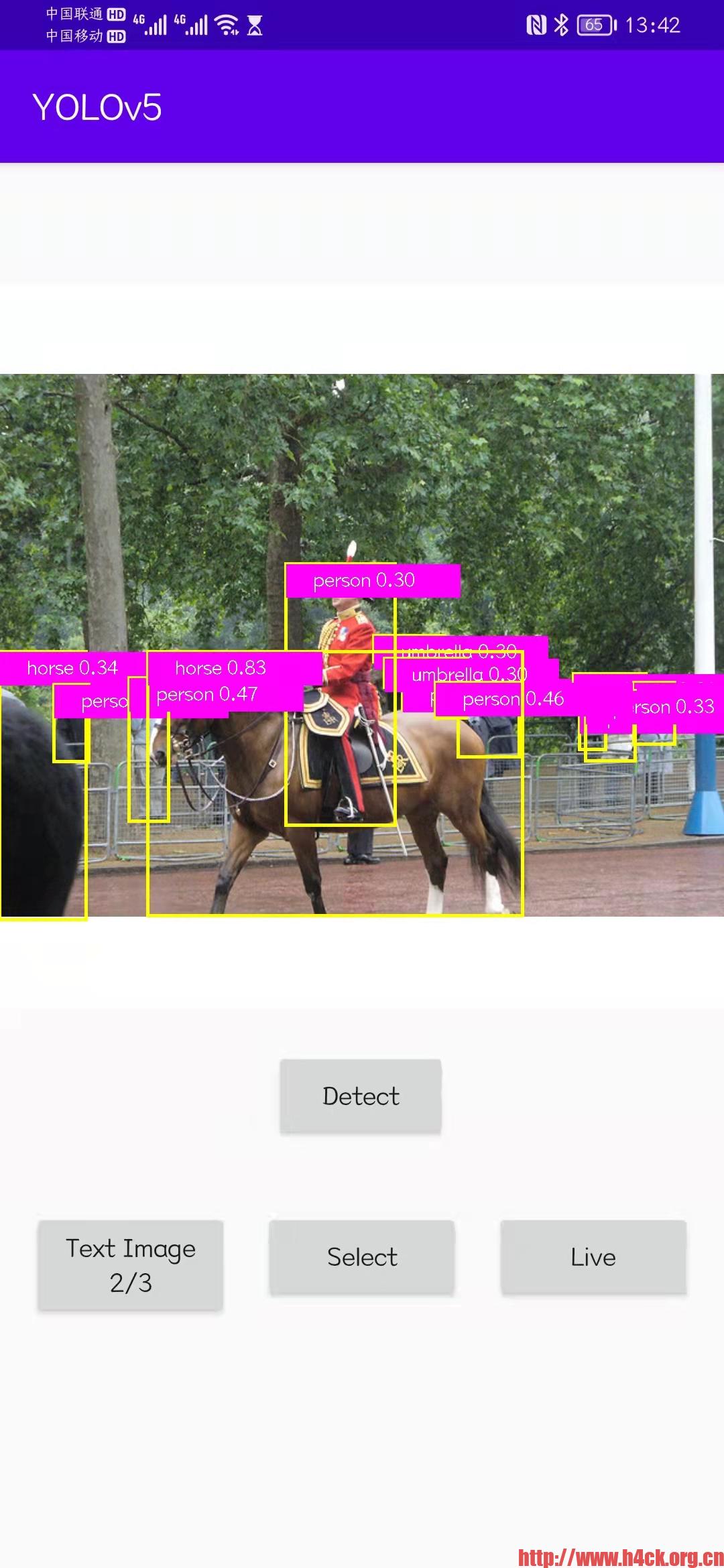
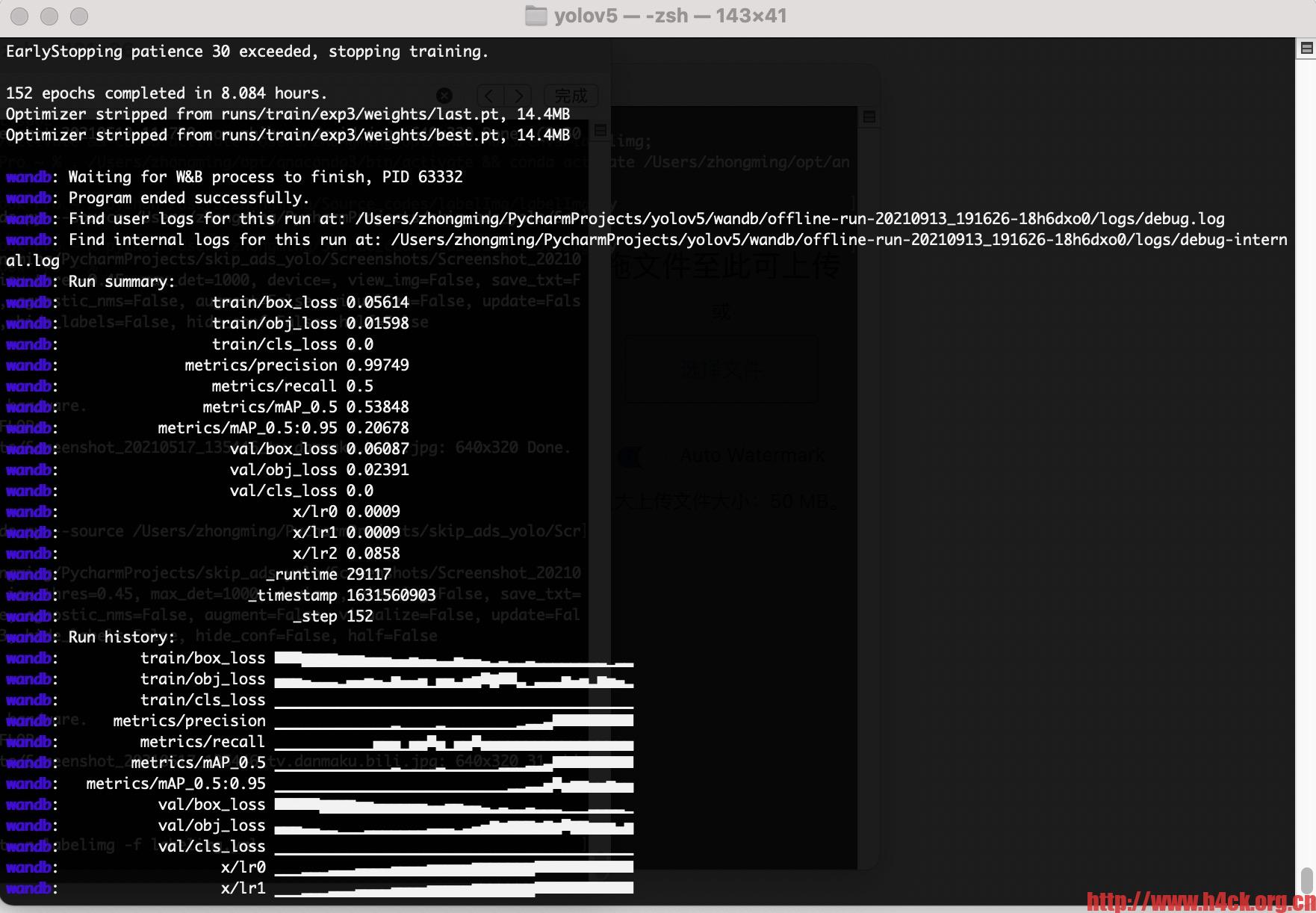
测试训练集二十几张图片,在m1 mac上的运行时间一共8.084 小时,共152 epochs。对于这个计算速度还是比较让人吃惊的,这个效率也太低了。对于需要处理图像的训练这个速度也无法让人接受。
152 epochs completed in 8.084 hours.
Optimizer stripped from runs/train/exp3/weights/last.pt, 14.4MB
Optimizer stripped from runs/train/exp3/weights/best.pt, 14.4MB
wandb: Waiting for W&B process to finish, PID 63332
wandb: Program ended successfully.
wandb: Find user logs for this run at: /Users/zhongming/PycharmProjects/yolov5/wandb/offline-run-20210913_191626-18h6dxo0/logs/debug.log
wandb: Find internal logs for this run at: /Users/zhongming/PycharmProjects/yolov5/wandb/offline-run-20210913_191626-18h6dxo0/logs/debug-